

Daimon Robotics et Galbot lancent RobOmni pour évaluer la perception tactile et la manipulation dextérique
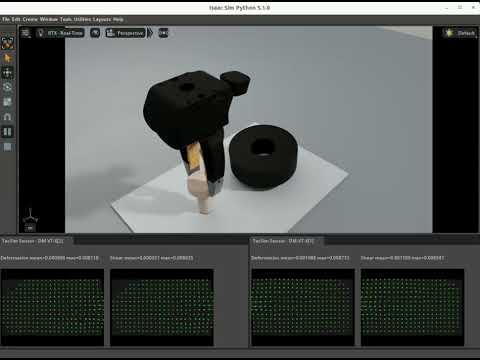
Daimon Robotics, entreprise de Hong Kong spécialisée dans la perception tactile et la manipulation dextre, a présenté RobOmni lors de l'ICRA 2026, en partenariat avec Galbot. Il s'agit du premier benchmark d'évaluation omni-modal intégrant la perception tactile pour les interactions physiques en robotique. La plateforme, construite sur NVIDIA Isaac Sim, standardise l'évaluation de tâches de manipulation au contact : saisie d'objets, insertion de précision, assemblage de composants et placement. RobOmni capture simultanément plusieurs flux de données, capteurs tactiles haute résolution au bout des doigts, vision RGB montée au poignet, état de la pince, trajectoires TCP et observations de caméras externes, pour évaluer les systèmes robotiques selon cinq dimensions : taux de succès, efficacité de manipulation, capacité de manipulation dextre, événements d'échec (glissement, coinçage, collision, nouvelle tentative) et robustesse de généralisation.
Ce lancement répond à un manque structurel dans l'industrie : l'absence de cadre standardisé pour mesurer l'apport réel du sens tactile par rapport à la perception purement visuelle. Sans benchmark unifié, il est impossible de comparer les systèmes, de quantifier les progrès ou d'identifier quelles données tactiles améliorent concrètement les tâches réelles. Pour les intégrateurs industriels et les décideurs B2B qui évaluent des bras manipulateurs pour des lignes d'assemblage ou de service, ce vide est critique : une manipulation fiable dans des environnements non structurés requiert de détecter le glissement, la déformation du contact ou la rigidité d'un matériau lors d'un emboîtement, autant de signaux que la vision seule ne peut pas capturer. RobOmni propose de quantifier systématiquement cet apport, ce qui permettrait notamment de comparer des architectures VLA (Vision-Language-Action) avec et sans retour tactile sur des tâches identiques.
Daimon Robotics a développé ses propres capteurs tactiles basés sur la vision, capables de mesurer non seulement la force de contact mais aussi la déformation, le glissement, les propriétés de matériau, la texture et la dureté, à haute fréquence et haute résolution. Galbot, partenaire du projet, apporte son expertise en robotique mobile et manipulation. Si aucune métrique de performance comparative ni timeline de déploiement commercial ne sont encore publiées, ce lancement reste à ce stade une annonce de framework de recherche, pas un produit expédié, le positionnement à l'ICRA 2026 signale une ambition de standardisation sectorielle. Les concurrents dans l'espace des benchmarks robotiques, notamment Google DeepMind (RoboVerse) et Meta (PARTNR), n'intègrent pas la modalité tactile comme dimension centrale d'évaluation. RobOmni comble potentiellement ce vide, à condition que la communauté adopte le framework comme référence commune.
Dans nos dossiers



